Waveshaper AI is a startup incubated at the Montreal-based startup foundry TandemLaunch.
Our objective is to make audio sound better using AI. We do this using research pioneered at Queen Mary University of London.
Audio and AI
The technology used by Waveshaper AI is based on a family of deep neural network architectures designed to accept raw digital audio samples as input, process them, and then output raw audio samples. This allows for the development of new types of audio signal processing systems that learn by listening, rather than being programmed or designed into hardware circuits.
Neural networks are a type of artificial intelligence modeled on biological information processing performed by neurons. Artificial neural networks are comprised of many individual simulated neurons that amplify or attenuate input signals based on their characteristics. The process of neural networks learning these characteristics automatically is called training, and modern computer hardware and AI algorithms make this a practical way to efficiently search for real solutions using this technology.
Applications using articial netural networks for image classification and natural language processing are well known. Audio data can also be fed into artificial neural networks to train them to recognize deep structure and relationships, and that’s what we set out to do with Waveshaper AI. Our mission is to make audio sound better and expand creative expression in audio using articial intelligence.
Enhancing Creativity
AI systems that learn what sounds good or sounds interesting are, in a way, mapping the human brain, since these are highly subjective criteria. In doing this, the Waveshaper AI neural networks take audio signals, decomposes them, and then compresses them to a deep latent representation. This process exposes hidden structure, which can then be manipulated creatively, and used to reconstruct a new signal with those features fully expressed.
Some of the audio processing effects and sounds that are loved by all have been essentially discovered by accident. AI will help untangle the noise of audio signals and open up untapped acoustic areas to explore.
Using AI as a technology to locate the deep features in audio data expands human intuition and creativity.
Analog to Digital
The standard digital form of sampled analog audio data is pulse-code modulation (PCM). The sample rate of the data is the rate at which samples were measured: the higher it is, the more information is captured about the original analog audio for each discrete unit of sampling time. The bit-depth is the amount of information stored per sampling measure. Common bit-depths are 16-bit (2-bytes per sample) and 24-bit (3-bytes per sample).
A sample rate of 44100 samples/second, or 44.1khz, is what was used for CD audio and was chosen based on the Nyquist-Shannon sampling theorem, which asserts that an ideal sample rate should be twice that of the maximum frequency that will be reproduced. The range of human hearing is 20khz to 20,000khz. This explains the common sampling rates of 44100 and 48100 samples per second: they target the optimal range of the human listener. 16-bit and 24-bit depth are common today for digital audio.
Real time
Real time audio processing needs to happen fast: within 2-3ms per channel to avoid perceptible latency, otherwise it cannot be used for streaming, live performances, broadcasts, etc. This has thus far created a challenge for using neural networks for processing audio as they are often very slow when the quantity of data is high, as is the case for multimedia content. Our goal has been to process audio through neural networks fast, as in, fast enough to do it in real time. We have achieved success in this using a number of techniques to create highly efficient networks optimized for audio, and packaging them into a runtime framework that we call the inference engine.
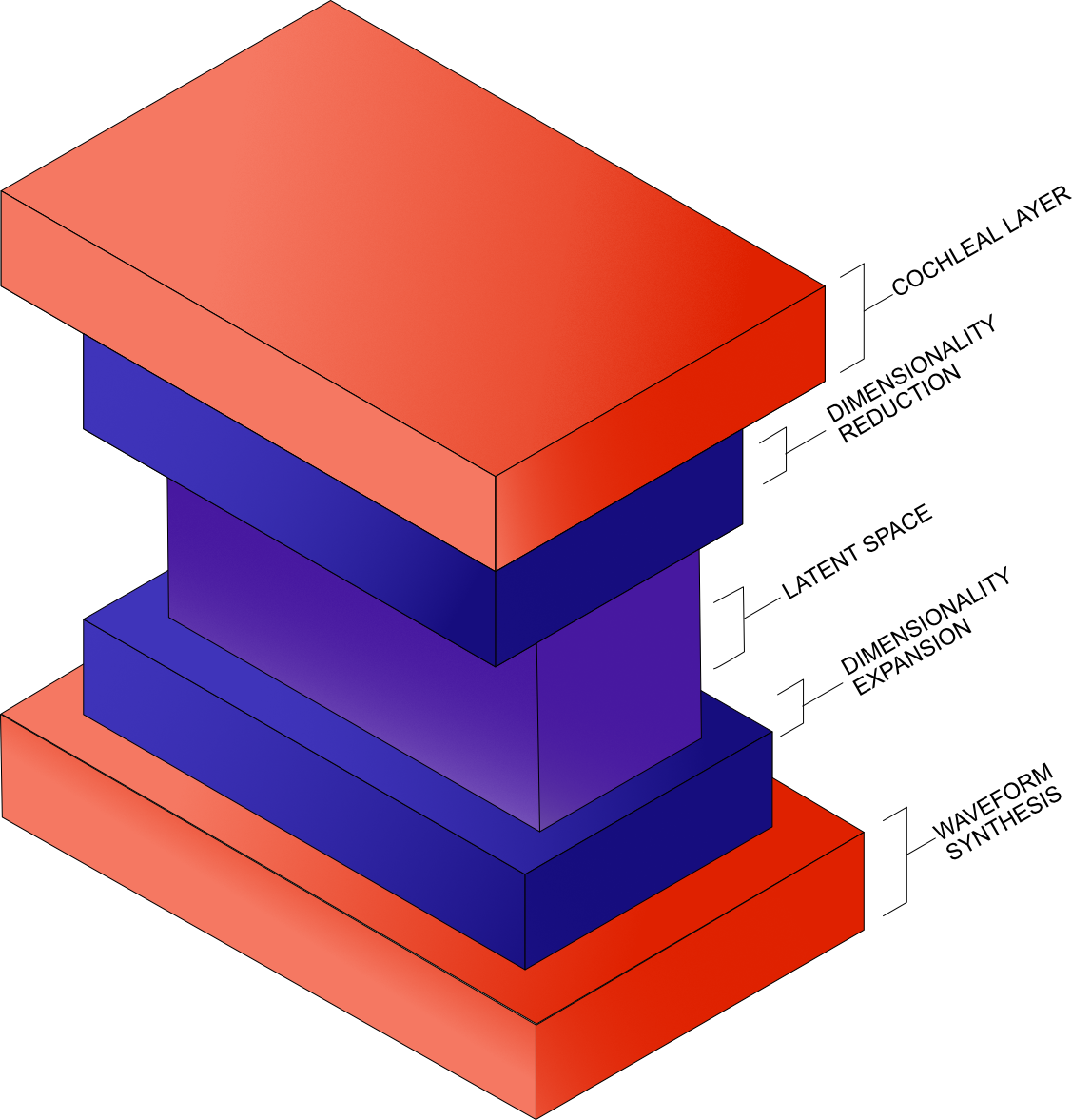
Inference Engine
Waveshaper has developed a new kind of modular audio processing platform, called the audio inference engine. It takes frames of raw audio as input and feeds them through a deep neural network. The network is composed of layers which are trained to decompose the signal, compress consituent frequency information, and then apply transformations. The output is a new signal.
The audio inference engine is something like a virtual machine, with the type of audio processing function simply data that is loaded into the neural network. To change how audio is being processed, just change the neural network parameters, which are simply data.
The Waveshaper AI inference engine is written to do this very fast and on multiple platforms.