One of the everyday challenges we have at Waveshaper is building systems that can consume any type of digital audio format. Audio data is rarely stored in raw PCM format; rather, various file formats exist, some of which compress audio information with lossy psychoacoustic models, such as MP3, while others are lossless. The WAV file format is one example that is very well-known. With WAV files, we need to get to the samples, and pull them out so we can process them. Let’s dive into what that means in practice, because there are a lot of weird WAV files out there in the wild.
WAV Shaping
A WAV file is a container for digital audio data. WAV files are comprised of chunks, which provide the structure for the file.
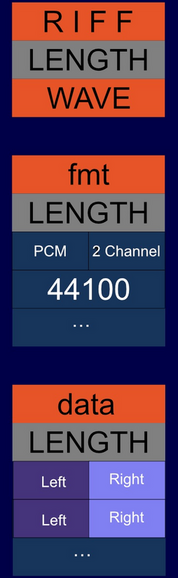
The first chunk in the file is the the RIFF descriptor, which includes the following information:
- A special tag (FOURCC identifier) comprised of 4 ASCII bytes: ‘R’,‘I’,‘F’,‘F’
- An integer value encoded as 4 bytes in little-endian byte order: size of the data less 8 bytes of this header
The RIFF data section follows immediately. A valid WAV file will have the first four bytes of this section set to the following ASCII bytes: ‘W’,‘A’,‘V’,‘E’.
While Waveshaper uses C++ and C for speed, we have created some simple Python code to demonstrate the basic ideas:
# Example code by Waveshaper AI
# Ladan Golshanara, September 2022
import os
import sys
filename = sys.argv[1]
print(filename)
f = open(filename,"rb")
try:
orig_file_size = os.path.getsize(filename)
print("Total file size on filesystem: ",orig_file_size)
riff_id = f.read(4)
print("First 4 bytes is the RIFF tag: ",riff_id)
size_bytes = f.read(4)
Additional structures within the WAV file format will follow immediately after the ‘WAVE’ tag. These are known as sub-chunks, and there are a few of them. Only the fmt and data sub-chunks matter for our purposes, but a WAV file processor should loop through all chunks to as assumptions about their order may be wrong.
The example Python code has been expanded below to do loop through the file looking for the fmt chunk:
# Example code by Waveshaper AI
# Ladan Golshanara, September 2022
import os
import sys
filename = sys.argv[1]
print(filename)
f = open(filename,"rb")
try:
orig_file_size = os.path.getsize(filename)
print("Total file size on filesystem: ",orig_file_size)
riff_id = f.read(4)
print("First 4 bytes is the RIFF tag: ",riff_id)
size_bytes = f.read(4)
print("Next 4 bytes is size of total sub chunks (total file size minus 8 header bytes): ", int.from_bytes(size_bytes, "little"))
wav_id = f.read(4)
print("Next 4 bytes should be the WAVE tag: ",wav_id)
while(True):
chunk_id = f.read(4)
chunk_size = int.from_bytes(f.read(4),"little")
print("Chunk tag: ",chunk_id)
print("Chunk size: ",chunk_size)
if (f.tell() == os.fstat(f.fileno()).st_size):
break
f.seek(chunk_size,1)
finally:
f.close()
The fmt chunk and the data chunk are required to successfully interpret the audio data.
The fmt chunk
The fmt chunk contains metadata describing the audio data, and it must come before the data chunk, as it informs the reader of the file about how to understand the audio data bytes. The fmt chunk is a binary structure comprised of the following mandatory fields:
- 4 bytes for storing the FOURCC identifier tag: ‘f’, ’m’, ’t’
- An integer value encoded as 4 bytes in little-endian byte order storing the size of the sub-chunk
- 2 byte format code (1 is PCM)
- 2 byte short storing the number of interleaved channels
- 4 byte integer encoded in little-endian byte order storing the sample rate
- 4 byte integer encoded in little-endian byte order storing the bytes per sample block: (sample rate * number of channels)/8
- 2 byte short encoded in little-endian byte order storing the bits per sample
The following code extracts these fields from the fmt chunk:
if chunk_id.startswith("fmt"):
bytes_read = 0
fmt_code = int.from_bytes(f.read(2),"little")
print(" - fmt code: ",fmt_code)
bytes_read += 2
num_channels = int.from_bytes(f.read(2),"little")
print(" - channels: ",fmt_code)
bytes_read += 2
sample_rate = int.from_bytes(f.read(4),"little")
print(" - samples per second: ",sample_rate)
bytes_read += 4
byte_rate = int.from_bytes(f.read(4),"little")
print(" - byte rate: ", byte_rate)
bytes_read += 4
block_align = int.from_bytes(f.read(2),"little")
print(" - block align: ", block_align)
bytes_read += 2
bits_per_sample = int.from_bytes(f.read(2),"little")
print(" - bits_per_sample: ", bits_per_sample)
bytes_read += 2
f.seek(chunk_size-bytes_read,1)
print("bytes remaining in fmt chunk: ",chunk_size-bytes_read)
continue
# Example code by Waveshaper AI
# Ladan Golshanara, September 2022
The data chunk
Once you have read the fmt chunk, you have enough information to interpret the data chunk: the bits per sample, the number of channels, etc.
The channel samples are interleaved in the data chunk; the bytes for each channel are stored consecutively, with the aggregate data for all channels forming a block.
Each sample will be stored as a sequence of bytes corresponding to the bit-depth: 16-bit WAV files will have samples that are 2 bytes long, 24-bit WAV files will have 3-byte samples. These byte values are to be converted to integers and scaled to floating point values between -1.0 and 1.0.
Rescaling
Obtaining a value between -1 and 1 can be accomplished using type conversion and division: divide the integer value by the maximum signed value that can be expressed using the number of bytes. In the case of 16-bit bit-depth, this is 32768, for 24-bit it is 8388608.
The following segment of code reads the first 10000 samples for all channels:
elif (chunk_id.startswith("data")):
bytes_read = 0
if fmt_found == False:
print("error: no fmt chunk, don't know how to interpret the data")
break
bytes_to_read = int(bits_per_sample/8)
# Note that the number of samples here is hard coded..
for i in range(10000):
print("num_channels: ",num_channels)
for chan in range(num_channels):
float_sample = 0.0
## Read the appropriate number of bytes for a sample, convert to float
int_sample = int.from_bytes(f.read(bytes_to_read),"little",signed=True)
if bits_per_sample == 16:
## Normalize to [-1,1) for 16-bits
float_sample = int_sample / 32768.0
elif bits_per_sample == 24:
## Normalize to [-1,1) for 24-bits
float_sample = int_sample / 0x800000
elif bits_per_sample == 32:
## Normalize to [-1,1) for 32-bits
float_sample = int_sample / 0x7fffffff
print("chan ",chan, ": ",float_sample)
bytes_read += bytes_to_read
f.seek(chunk_size-bytes_read,1)
continue
# Example code by Waveshaper AI
# Ladan Golshanara, September 2022
The complete code follows:
# Example code by Waveshaper AI
# Ladan Golshanara, September 2022
import os
import sys
## Filename is the first argument
filename = sys.argv[1]
## Create a file handle
f = open(filename,"rb")
try:
## Located fmt chunk
fmt_found = False
num_channels = 0
bits_per_sample = 0
## Get the original filename
orig_file_size = os.path.getsize(filename)
print("Total file size on filesystem: ",orig_file_size)
## Read the first 4 bytes of the file
riff_id = f.read(4)
print("First 4 bytes should be the RIFF tag: ",riff_id)
## Read the next 4 bytes of the file
size_bytes = f.read(4)
print("Next 4 bytes is size of total sub chunks (total file size minus 8 header bytes): ", int.from_bytes(size_bytes, "little"))
## Read the next 4 bytes of the file
wav_id = f.read(4)
print("Next 4 bytes should be the WAVE tag: ",wav_id)
## Now we may have an arbitrary number of chunks, need to loop to find the two we care about: fmt and data
while(True):
## Read chunk header
chunk_id = f.read(4).decode("ascii")
chunk_size = int.from_bytes(f.read(4),"little")
print("Chunk tag: ",chunk_id)
print("Chunk size: ",chunk_size)
## Do fmt chunk
if chunk_id.startswith("fmt"):
## Set the flag to true, we have encountered the fmt chunk
fmt_found = True
## Because we might stop reading the chunk before it is done,
## track the number of bytes of the chunk we have read
## so we can skip the rest, if there is more than the fields we
## extract
bytes_read = 0
## Read the fmt code (PCM = 1)
fmt_code = int.from_bytes(f.read(2),"little")
print(" - fmt code: ",fmt_code)
bytes_read += 2
## Read the number of channels
num_channels = int.from_bytes(f.read(2),"little")
print(" - channels: ",num_channels)
bytes_read += 2
## Read the sample rate
sample_rate = int.from_bytes(f.read(4),"little")
print(" - samples per second: ",sample_rate)
bytes_read += 4
## Read the byte rate
byte_rate = int.from_bytes(f.read(4),"little")
print(" - byte rate: ", byte_rate)
bytes_read += 4
block_align = int.from_bytes(f.read(2),"little")
print(" - block align: ", block_align)
bytes_read += 2
bits_per_sample = int.from_bytes(f.read(2),"little")
print(" - bits_per_sample: ", bits_per_sample)
bytes_read += 2
## We read what we wanted from the fmt tag,
## skip the rest
f.seek(chunk_size-bytes_read,1)
print("bytes remaining in fmt chunk: ",chunk_size-bytes_read)
continue
elif (chunk_id.startswith("data")):
bytes_read = 0
if fmt_found == False:
print("error: no fmt chunk, don't know how to interpret the data")
break
bytes_to_read = int(bits_per_sample/8)
# Note that the number of samples here is hard coded..
for i in range(10000):
print("num_channels: ",num_channels)
for chan in range(num_channels):
float_sample = 0.0
## Read the appropriate number of bytes for a sample, convert to float
int_sample = int.from_bytes(f.read(bytes_to_read),"little",signed=True)
if bits_per_sample == 16:
## Normalize to [-1,1) for 16-bits
float_sample = int_sample / 32768.0
elif bits_per_sample == 24:
## Normalize to [-1,1) for 24-bits
float_sample = int_sample / 0x800000
elif bits_per_sample == 32:
## Normalize to [-1,1) for 32-bits
float_sample = int_sample / 0x7fffffff
print("chan ",chan, ": ",float_sample)
bytes_read += bytes_to_read
f.seek(chunk_size-bytes_read,1)
continue
## If EOF, break out of the loop
if (f.tell() == os.fstat(f.fileno()).st_size):
break
## Otherwise, skip chunk
f.seek(chunk_size,1)
finally:
## Close the file
f.close()
Hope this is useful.